A Matter of Time
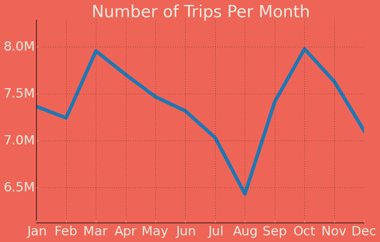
If we look at the number of cab rides month-over-month, we can see highs in March and October, and a minimum in August.
If we looked at weather data, we could probably find a relationship with some 'pleasantness' factor, and perhaps also some relationship
with seasonal business and event data.
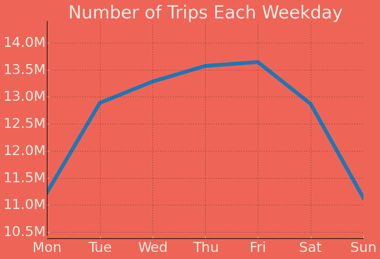
Hour of The Week
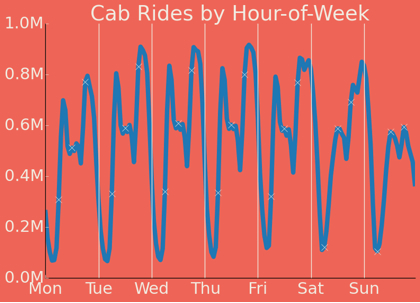
There's a corresponding trough that happens afterward - the lowest volume of rides for that 24 hour cycle. On most days it occurs at around 2am, but on Friday night and Saturday night, the lowest volume doesn't occur until about 6am.
The Drinking Hours

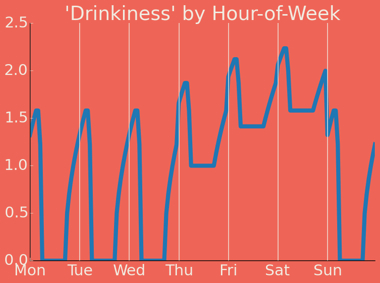
It's straightforward to map a taxi pickup time to this model, but we need to revisit our geographic data for the final part of our model: how we map our 'drinkiness' to actual stumbling distance.
The End
At last! We now have a 'drinkiness' factor for both the time and location of relevant cab rides. To find if there's a relationship with drinkiness and tip percentage, we could simply use regression. In some cases linear regression is not enough to tell a full story.

If we look for a linear trend, the r-squared comes back as .02...no relationship. If we segment the population into the top and bottom quartiles, we can compare averages. Doing this, we find that the LEAST drunk people actually tip more, by about 0.06%. Only if we investigate the full distribution do we see some real differences.
3.10% of drunk people leave no tip at all, compared to 2.61% of sober people.
3.50% of drunk people leave an exorbitant tip (>30%), compared to 3.37% of sober people.
After all this, we are awarded with the insight that drunk people may have more extreme views than sober people.
I asked Steve if he would hail a cab over to have drinks with me, so we could discuss next steps, but he didn't believe that you can get a cab in Los Angeles.
Data Science.